Backing up data is a lot like insurance—we set it up, forget about it, and then panic when we need it most. A weak backup and restore strategy can turn a stressful situation into a disaster. In recent years, we started noticing some weak points in our own backup strategy and knew it was time to take action. In this post, we’ll take you behind the scenes and show how Wealthfront’s DevOps team transformed database backups into a speedy, reliable process.
Databases at Wealthfront
Let’s step back a bit and give you a quick rundown on our database architecture. Wealthfront’s production databases run as MariaDB instances on bare-metal servers in co-located data centers. Each database runs in a cluster with multiple read-only replicas. The replicas provide an environment for ETL processes, one-off queries, and the subject of this blog post: backups!
We are growing! But so are our backups
As Wealthfront’s client base grows and our engineers continue to build amazing new features, our databases grow as well. As a result, we have bigger and bigger backups. Our legacy strategy involved taking a logical backup of the full database every night. This strategy leveraged the mysqldump tool to create a SQL dump of the whole database. We would take this dump—stored as a .sql file—compress it, encrypt it, and upload it to AWS S3 every night.
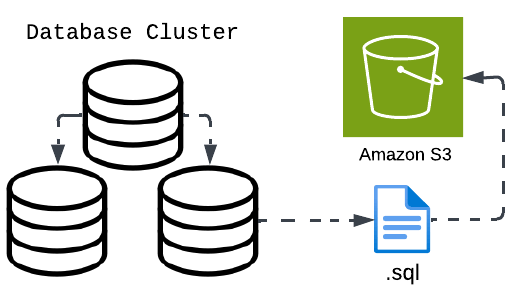
This is a fine strategy which worked for us for many years, but the problem we now faced was the sheer growth of our data. Our databases currently range in size from 8 to 14 terabytes each, meaning the mysqldump tool would have to parse TBs of data each night. This also meant our backups, after being compressed and encrypted, were between 900GB and 1.2TB. On our largest databases’ backup times were creeping up to 24 hours.
This caused a few problems:
- During backups, replication was stopped on the async replica where the process was running. This caused significant lag and left only a few hours for the replica to play catch-up.
- These backups took up a lot of space on disk while being constructed, and we had to allocate that space when designing our server storage profile.
- Restoring from these backups took even longer. Since a restore consists of re-playing terabytes of SQL, our largest databases took over a week to restore!
Now the obvious solution to this problem would be to split up/shard our databases. While this is the solution we wanted and are working towards over the long term, we needed a quicker fix!
Why not just snapshot?
Months before even tackling this problem, someone made the statement: “You know what? Wouldn’t it be super nice if we could just snapshot our backups?” The idea stuck! It came up every time we faced backup issues. So, when we were exploring new solutions, snapshotting became a top contender.
Considering snapshots for our databases meant moving from a full backup at the application layer to an incremental backup at the block device layer.
Incremental Backups
Rather than backing up a whole database every night, only the changes made to a database since the previous backup would be captured
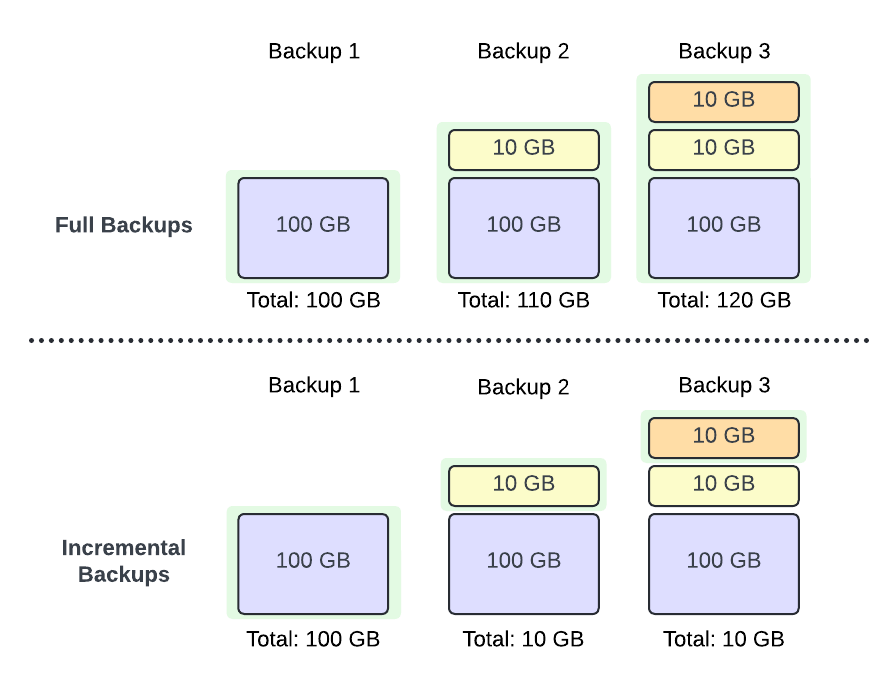
Block-level Backups
Rather than taking a logical backup with tools like mysqldump, which interact with the MariaDB application directly, we would back up the whole database partition at the device block level. This is a good option for us as we use the InnoDB storage engine with our databases, which stores data on disk in .idb files.
For example, for a database named db with the following tables: orders, products, users. We can see the associated files on disk
$ tree /var/lib/mysql/db/ | grep ibd
├── orders.ibd
├── products.ibd
└── users.ibdCode language: JavaScript (javascript)During our research, we found that this incremental, block-level approach to backups delivered the features we desired. Since snapshots are copy-on-write, backups are nearly instantaneous and easy to restore when needed. With this new plan in place, we moved onto the next step: building it out!
A small addition with big value
As mentioned before, our databases run on bare-metal hardware, thus the most obvious backup solution was to use LVM snapshots. However, there was a concern: storage! To support this solution, we would have to allocate space on a NAS or SAN to store snapshots reliably, and then write tooling to create, manage, and restore snapshots. We could have done that, but why reinvent the wheel?
AWS already provides different snapshotting features, so we just needed to get our data into an AWS environment. To accomplish this, we augmented our database clusters with an additional replica that runs in AWS.
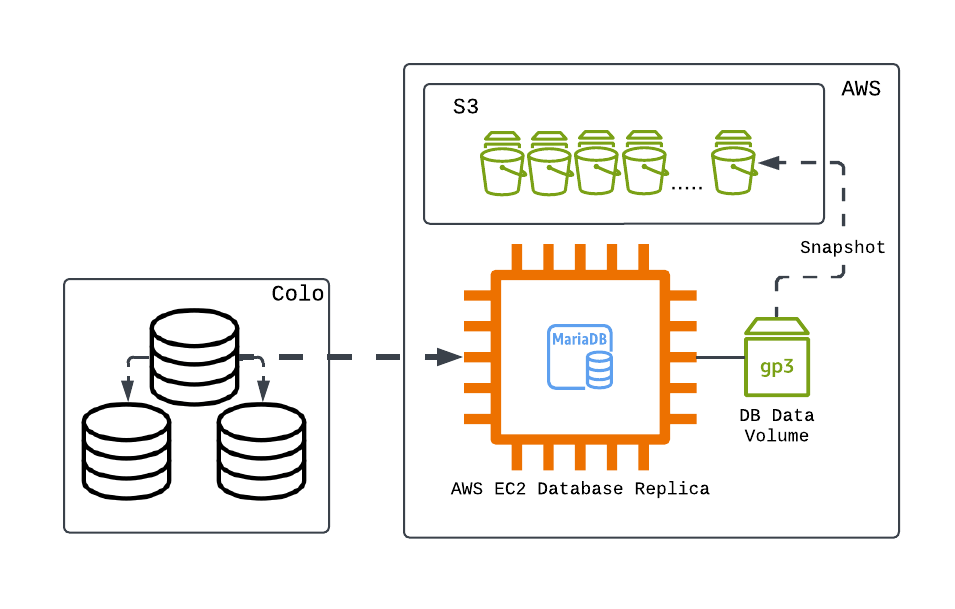
Easy peasy! Now all we have to do is tell AWS when to take a snapshot. Right?
Not just the push of a button
Now that we had the design and infrastructure in place, it was time to start snapshotting. But, as with most engineering problems, that was easier said than done.
Since our replicas are “online” we can’t just trigger a snapshot willy-nilly. If we snapshot with data in-flight, we will have missing or corrupted data in our backups. So, to solve this problem, we decided on taking the following steps for our backups:
- Correctness check: Ensure the volume we are snapshotting is correct.
- Stop replication: We don’t want data to be written to the replica while a snapshot is being taken.
- Flush tables: Commit all data in memory to disk.
- Freeze filesystem: Put underlying volume in a steady state before snapshotting.
- Take snapshot: Trigger snapshot of the EBS volume.
- Thaw filesystem: Unfreeze after snapshot is taken.
- Restart replication: Start replication thread and allow it to catch up.
To manage this whole flow, we initially looked at an additional AWS product, the Data Lifecycle Manager (DLM), which would allow us to set schedules for snapshots and set retention policies on them, which is exactly what we wanted. Sadly, there was a gotcha we didn’t expect: DLM only supports running pre/post scripts for instance snapshots (AKA AMIs) but our design involved volume snapshots. Without this, we couldn’t run the preparation steps we needed.
But hey, we’re engineers! So after a few weeks of banging our heads together, we put out a simple-to-use tool (very creatively called snap) to prepare and trigger snapshots. We rolled it out to our shiny new replicas in AWS, and voila! Snapshots!
Getting our data back
What good is a backup if you can’t use it? We now had a super fast, fully automated backup strategy with an un-automated, toilsome restore process. It was time to fix that! There were only two steps we needed to automate:
- Restore an EBS snapshot (to some temporary EC2 instance)
- Copy data from the new volume to wherever it needs to go
Simple enough! We added a restore option to our snap tool to accomplish this. It creates an on-demand EC2 instance, restores a snapshot to this instance, then copies the data over to a specified destination host. We even took it a step further and created another tool (very creatively called dbmover) that runs correctness checks against the destination server before running the data copy process.
Squashing the bugs
As with any new system, there are bound to be some gotchas here and there. This new backup system was no exception to that. Here are some of the interesting ones:
Prepared transactions
The first time we tried to restore from these new backups, we had MariaDB fail to start up. Not a good feeling. When looking into our logs we saw the following errors:
[ERROR] Found 2 prepared transactions! It means that mysqld was not shut down properly last time and critical recovery information (last binlog or tc.log file) was manually deleted after a crash. You have to start mysqld with --tc-heuristic-recover switch to commit or rollback pending transactions.
[ERROR] AbortingCode language: CSS (css)The quick fix was basically following the instruction in the error output: We added tc-heuristic-recover=commit to our my.cnf file and then restarted MariaDB. However, restarting MariaDB multiple times on every restore and expecting failures is not ideal. After some investigation, we found that our backup steps were running too fast in sequence. Specifically, we were freezing the filesystem too soon after flushing our tables to disk. Adding a time.Sleep(5) between these steps did the trick!
Index corruption
After a few weeks of running databases restored from snapshots, we noticed that there were corrupted indexes on a few of our tables. After investigating a bit, we ended up hitting a brick wall, at least until we looked at our backup replicas carefully. Turns out our backup source itself had corrupted indexes which carried over to our snapshots. A simple OPTIMIZE TABLE on the backup source fixed the issues. We theorized that improperly copying data around was the culprit. We eventually restaged our backup replicas again from a clean source and got it right. In addition, we decided to add monitoring for corruption as a part of our backup validation strategy.
Snapshot optimization
When restoring snapshots from EBS, the blocks of data are lazy loaded onto the volume. Sadly this hurts our restoration time because we want full I/O capacity when we start transferring data. To get around this we take some measures to pre-warm our restored volumes before transferring. This does still cause a bit of delay along with its resulting cost. We are exploring more solutions to improve this.
The results
Now for what we really care about. Did this help? Yes! We saw our backup times cut from hours to seconds! In terms of restoration, we have seen the 5-7 day restore time drop to a matter of hours!
Our fast backup times mean we no longer have laggy replicas, and our shift to AWS snapshots has dropped the number of backup failures to zero. Having quicker restores has also made the process of spinning up a new production database more commonplace. The changes we made open up a lot more avenues for improving our database infrastructure such as improving backup validation and empowering engineers to develop against sandbox databases.
Conclusion
At Wealthfront, we have a culture that emphasizes proportional investment and automation. When elements of our infrastructure cause us toil, we are empowered to take time to improve it. This project put that philosophy into practice. Switching to this new backup strategy has created a huge sigh of relief for our team. We can now focus on designing improvements to our database infrastructure instead of having to constantly react to it. In addition, this project was the first of its kind at Wealthfront. Using AWS to enhance the functionality of our data-center workloads ultimately resulted in a unique solution we are proud of!
Disclosures
The information contained in this communication is provided for general informational purposes only, and should not be construed as investment or tax advice. Nothing in this communication should be construed as a solicitation or offer, or recommendation, to buy or sell any security. Any links provided to other server sites are offered as a matter of convenience and are not intended to imply that Wealthfront Advisers or its affiliates endorses, sponsors, promotes and/or is affiliated with the owners of or participants in those sites, or endorses any information contained on those sites, unless expressly stated otherwise.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Please see our Full Disclosure for important details.
Investment management and advisory services are provided by Wealthfront Advisers LLC (“Wealthfront Advisers”), an SEC-registered investment adviser, and brokerage related products, including the Cash Account, are provided by Wealthfront Brokerage LLC (“Wealthfront Brokerage”), a Member of FINRA/SIPC. Financial planning tools are provided by Wealthfront Software LLC (“Wealthfront Software”).
Wealthfront Advisers, Wealthfront Brokerage, and Wealthfront Software are wholly-owned subsidiaries of Wealthfront Corporation.
Copyright 2025 Wealthfront Corporation. All rights reserved.