Our analytics team plays a vital role in maintaining high-quality data that drives everything from key reports to experiments aimed at improving our products. Ensuring data reliability is critical, and to achieve this, we’ve built a robust SQL testing library for Athena.
A strong data foundation isn’t just about accuracy—it’s about reliability. That’s why testing is at the core of our engineering culture, not an afterthought. Inspired by these principles, we treat testing as a first-class citizen in our development process. From automated checks in our ETL pipelines to SQL validation libraries that proactively catch errors, we ensure that data integrity is built into everything we do.
To improve efficiency for data analytical pipelines, we standardized on Athena SQL over EMR-based pipelines due to its simplicity, cost-effectiveness, and ease of use. However, this shift introduced a challenge: testing in Athena SQL isn’t as straightforward as it is in EMR. Since testability is essential for maintaining data integrity, we needed to find a way to bridge that gap.
As we explored solutions, we found that no open-source projects fully met our needs. We considered SDF, which offers promising SQL testability features, such as local query execution and a structured approach to SQL transformations. However, when we began developing our library, SDF was still a relatively new product, and its capabilities were evolving. Additionally, it lacked Athena integration, which is critical for our workflows. While SDF provides a way to work with test data using “seeds,” it does not offer native Airflow integration, making it difficult to incorporate into our pipeline orchestration.
Given these limitations, we needed to take a different approach to ensure data integrity, reliability, and efficiency in our Athena SQL pipelines. Since our engineering culture values building over buying, we chose to develop our own SQL testing library – one designed specifically for Athena and our workflows – rather than trying to retrofit an existing tool that lacked key integrations.
In this blog, we’ll share:
- How we built a SQL testing library for Athena.
- What we learned along the way—challenges, solutions, and best practices.
Let’s dive in!
Design Principles
As we built our SQL testing library for Athena, we kept few key principles in mind:
- Zero or Minimal Footprint – Our tests should avoid creating any artifacts whenever possible. If temporary tables or views are needed, they should be ephemeral and automatically cleaned up after execution. This ensures our datasets remain pristine, prevents unnecessary storage costs, and keeps our data environment clutter-free.
- Ease of Use & Extensibility – Writing and maintaining test cases should be as simple as writing SQL. Analysts and engineers should be able to easily add, modify, and extend tests without needing complex configurations or deep technical expertise.
- Dynamic & Adaptive Testing – Instead of relying solely on predefined test cases, our library should have the ability to automatically surface new issues as data evolves. This means incorporating anomaly detection, schema drift checks, and business-rule validations that can dynamically adjust to changing data patterns.
Beyond these, we also focused on:
- Integration with CI/CD – Testing should be an automated step in our data pipeline, ensuring that issues are caught before they impact production.
- Clear & Actionable Feedback for Reproducibility – When a test fails, it should provide meaningful insights to help engineers quickly diagnose, reproduce, and fix the issue.
By following these principles, we built a lightweight yet powerful SQL testing library that helps maintain the integrity of our Athena-based pipelines. In the next section, we’ll dive into how we did it.
Building a Mental Model for SQL Processing
At its core, SQL is all about working with data—it reads from source tables, processes it, and writes the results to a target table. But SQL workflows aren’t always a simple one-way street. In some cases, especially when building cumulative tables, SQL needs to read from and write to the same target table in a single query.
Example: Incremental Data Processing
Imagine a table that’s partitioned by date, where each day’s data builds on the previous day’s results. A typical SQL query in this scenario would:
- Read yesterday’s partition from the target table.
- Combine it with today’s new data to generate updated results.
- Write the updated dataset back to the target table, creating a new partition for today.
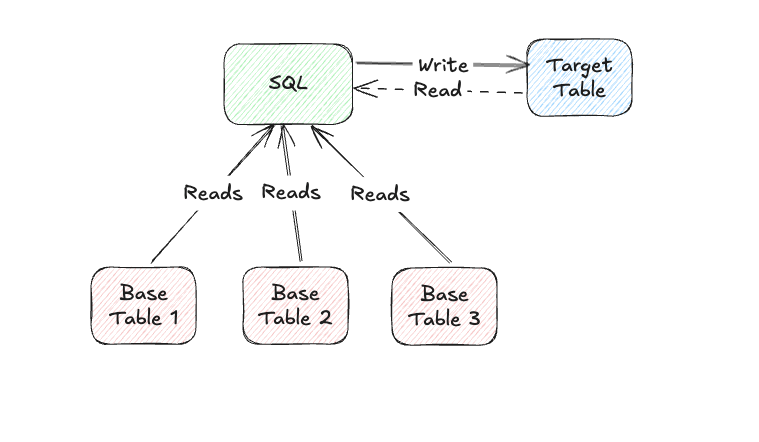
Now let’s go over our key design choices.
Physical Tables/Views vs. CTEs: Choosing the Right Approach for SQL Testing
One of the first design decisions we faced was how to structure test data for our SQL tests. We needed a way to run queries against a dataset that mimicked real-world conditions without leaving unnecessary artifacts behind.
A traditional approach would be to create physical test tables in a separate database, populating them with test data at runtime. While this method provides persistence and allows for complex test scenarios, it directly conflicted with our “Zero or Minimal Footprint” principle—we wanted to avoid creating and managing extra tables just for testing.
Instead, we opted for a cleaner and more lightweight approach: using Common Table Expressions (CTEs) to generate test data on the fly.
By leveraging CTEs:
- No physical artifacts – Test data is defined within the query itself and disappears after execution.
- Simplified test setup – No need to manage the test table lifecycle or clean up after tests.
- Better portability – Tests can be easily shared and run across different environments without worrying about schema dependencies.
This approach allowed us to keep our SQL testing library efficient, flexible, and non-intrusive while ensuring that every test could execute in a controlled, self-contained manner.
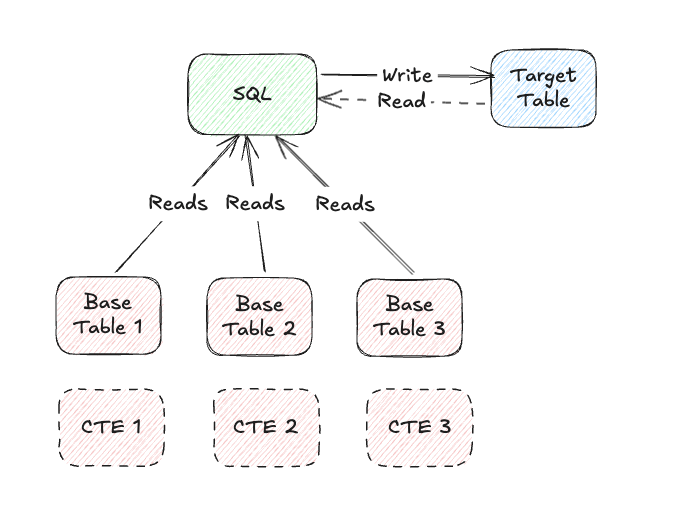
Modeling the Base Tables for SQL Testing
After deciding to use CTEs for test data, the next challenge was figuring out how engineers should define the structure of these test tables and generate realistic test data efficiently.
At Wealthfront, we standardize all our upstream operational tables using Avro schemas. Avro is a great choice because it provides a JSON representation (.avsc) of our data models written in definition language (.avdl), making it easy to work with. To streamline test data creation, we leveraged these existing schemas to automatically generate Python classes that represent our data structures.
Why Python? Since all our SQL queries are part of Airflow DAGs, which are written in Python, it made sense to use Python for defining and generating test data as well. This ensures consistency across our workflows and allows us to seamlessly integrate test data creation into our existing pipeline setup.
How We Automated Schema Generation
Rather than manually writing Python models for each table, we found a great open-source library—dataclasses-avroschema. This library allows us to:
- Automatically generate Python dataclasses from our JSON-based Avro schemas.
- Easily create test data by instantiating these Python classes using fake() method.
- Ensure schema consistency between our test data and real operational tables.
By adopting this approach, we eliminated redundant work, reduced errors, and made test data creation a breeze. Now, engineers can quickly model tables and generate structured, schema-compliant test data without any manual effort.
Sample Code
Maven Plugin Code – Generate AVSC (Json Representation) from AVDL (Avro Definition Language)
package com.wealthfront.data.maven;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.avro.Protocol;
import org.apache.avro.compiler.idl.Idl;
import org.apache.avro.compiler.idl.ParseException;
import org.apache.avro.tool.IdlTool;
import org.apache.maven.plugin.AbstractMojo;
import org.apache.maven.plugin.MojoExecutionException;
import org.apache.maven.plugin.MojoFailureException;
import org.apache.maven.plugins.annotations.LifecyclePhase;
import org.apache.maven.plugins.annotations.Mojo;
import org.apache.maven.plugins.annotations.Parameter;
import com.google.common.annotations.VisibleForTesting;
@Mojo(name = "avro-avsc-generate", defaultPhase = LifecyclePhase.GENERATE_SOURCES)
public class AvroIdlToAvscGenerator extends AbstractMojo {
@Parameter(property = "inputDir", required = true)
private File inputDirectory;
@Parameter(property = "outputAvscDirectory", required = true)
File outputAvscDirectory;
private final IdlTool avroTool = new IdlTool();
@Override
public void execute() throws MojoExecutionException, MojoFailureException {
if (!outputAvscDirectory.exists()) {
outputAvscDirectory.mkdirs();
}
AvroIdlParser parser = new AvroIdlParser(inputDirectory);
for (File avdlFile: parser.getAvdlFiles()){
try {
generateAvscFile(avdlFile, outputAvscDirectory);
} catch (IOException | ParseException e) {
throw new RuntimeException(e);
}
}
}
@VisibleForTesting
void generateAvscFile(File avdlFile, File outAvscDir) throws IOException, ParseException {
final Idl parser = new Idl(avdlFile);
final Protocol protocol = parser.CompilationUnit();
File outputDirectory = new File(outAvscDir + "/" + protocol.getNamespace().replace('.', '/'));
if (!outputDirectory.exists()) {
outputDirectory.mkdirs();
}
List<String> toolArgs = new ArrayList<>();
toolArgs.add(avdlFile.getAbsolutePath());
toolArgs.add(outputDirectory.getAbsolutePath() + "/" + protocol.getName() + ".avsc");
try {
avroTool.run(System.in, System.out, System.err, toolArgs);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
Code language: Java (java)Generate Python Model class from AVSC (Json Representation)
from dataclasses_avroschema import ModelGenerator, ModelType
model_generator = ModelGenerator()
schema = {
"type": "record",
"namespace": "com.kubertenes",
"name": "AvroDeployment",
"fields": [
{"name": "image", "type": "string"},
{"name": "replicas", "type": "int"},
{"name": "port", "type": "int"},
],
}
result = model_generator.render_module(
schemas=[schema],
model_type=ModelType.AVRODANTIC.value,
)
# save the result in a file
with open("models.py", mode="+w") as f:
f.write(result)
Code language: Python (python)Modeling the Target Table for SQL Testing
While our base tables follow a well-defined Avro schema, target tables—where processed data is stored—are a bit different. These tables are written in Parquet format and don’t have a predefined Avro model. However, their structure is still defined within our Airflow DAGs using a custom GlueCreateTable Airflow Operator, which ensures a consistent table schema.
To bring these target table definitions into our SQL testing library, we took a similar approach:
- Extracting the column structure from the GlueCreateTable operator.
- Using the same dataclasses-avroschema library to generate Python models.
- Automating model updates to keep schema definitions up to date.
To make this process seamless, we also built a simple Makefile utility that allows engineers to quickly update their local models when developing new test cases. This ensures that every test aligns with the latest target table structure without requiring manual updates.
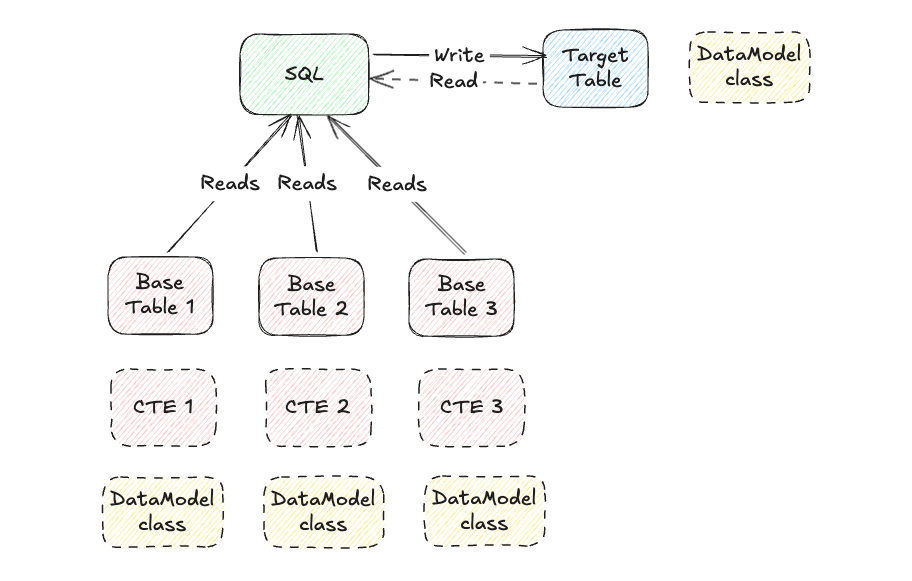
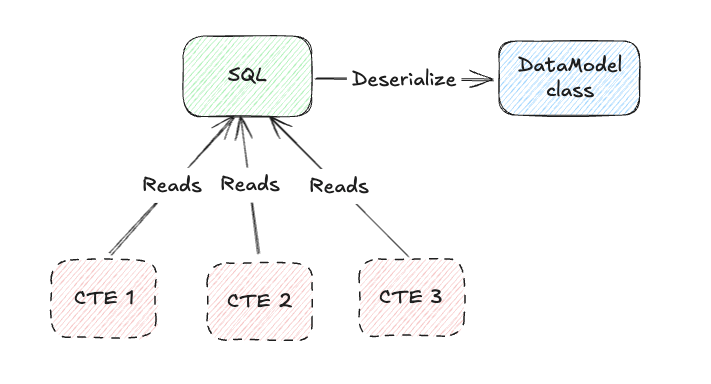
Injecting Models into SQL for Testing
Once we’ve defined our data models and generated test data, the next challenge is seamlessly injecting that data into the SQL under test. This ensures that our queries run against structured, realistic test datasets without requiring physical tables.
How We Inject Models into SQL:
- Convert Test Data into CTEs – The first step is transforming the fake data from our models into Common Table Expressions (CTEs). These CTEs act as in-memory representations of our test tables, eliminating the need for physical database artifacts.
- Decorate SQL with Generated CTEs – Once the CTEs are created, we prepend them to the original SQL query. This ensures that when the SQL runs, it references the test data instead of querying actual tables.
- Rewrite SQL to Replace Table Names with CTEs – Simply adding CTEs isn’t enough—we also need to modify the SQL query so that it refers to these temporary test datasets instead of production tables. To do this, we use SQLGlot, an open-source SQL parser and transpiler. SQLGlot allows us to allows us to Parse SQL into an Abstract Syntax Tree (AST), making it easy to analyze its structure, and transform SQL dynamically, replacing real table names with their corresponding CTE references.
Why This Approach Works Well
- No changes required in the original SQL query – The library automatically injects test data, allowing engineers to focus on writing business logic.
- Supports different SQL dialects – SQLGlot helps us handle Athena SQL transformations seamlessly.
- Lightweight & efficient – The entire injection process happens at runtime, requiring no persistent changes to the database.
By automating model injection into SQL, we’ve made it easier than ever to test queries in an isolated, controlled environment, ensuring that our pipelines run smoothly without unexpected failures.
Choosing the Right Query Execution Environment for SQL Testing
When it came to running SQL test cases, we had two main options:
- Set up a Docker container with Trino, matching the version used by Athena.
- Create a separate Athena workgroup dedicated to running SQL test cases.
After careful evaluation, we decided to go with a separate Athena workgroup, and here’s why:
Simple & Seamless Setup – Spinning up a new Athena workgroup required minimal configuration compared to maintaining a Trino Docker container.
Better Security Controls – We configured a dedicated SQL testing user with permissions that restrict access to production Glue tables. This ensures that test cases run in complete isolation, without any risk of modifying or even reading production data.
Built-in Resource Management – Athena workgroups allow us to enforce query limits, such as the maximum number of bytes a query can process. This prevents runaway queries from consuming excessive resources and keeps our test environment lightweight and controlled.
Why We Avoided the Docker-based Trino Approach
- While Trino is the open-source engine that Athena is based on, AWS may have made custom modifications that aren’t reflected in the public Trino release.
- This could lead to inconsistencies between local test execution (using Trino in Docker) and actual execution in Athena.
- Maintaining an up-to-date Trino image that perfectly matches Athena would have required additional effort and could introduce unexpected mismatches.
By leveraging a dedicated Athena workgroup, we struck the right balance between ease of setup, security, and execution consistency—ensuring that our SQL tests run in an environment that closely mirrors production while staying fully isolated.
SQL Data Output Validation: Enforcing Data Integrity
Once a SQL query runs, the next crucial step is validating the output to ensure it aligns with our expected data model. Instead of treating the SQL result as just another dataset, we deserialize it directly into our Target Table data model – enforcing structured validation at every step.
How This Helps with Validation
By mapping SQL output to a strongly typed data model class, we can automatically verify that:
- Values conform to expected types – If a column is defined as an Enum or Literal type in the model, the deserialization process ensures that the SQL output contains only valid, predefined values.
- Consistency is enforced – This helps establish a semantic data contract with stakeholders, ensuring that SQL transformations maintain expected business rules.
Using Pydantic for Robust Type Validation
To make validation seamless, we leveraged dataclasses-avroschema, which natively integrates with Pydantic—one of the most widely used data validation libraries in Python. This allows us to:
- Automatically enforce type constraints during SQL output validation.
- Catch mismatches early before data moves further down the pipeline.
With this approach, we’ve built a robust SQL testing library that not only validates raw query results but also ensures every field is semantically correct and contractually reliable.
Sample Code
Custom Pydantic types(WfDateStr,WfDateTimeStr, WfAnyValidDateTimeStr)
import dataclasses
import datetime
import typing
import pendulum
from dataclasses_avroschema.faker import fake
from dataclasses_avroschema.fields import mapper
from dataclasses_avroschema.pydantic.fields import PydanticField
from pydantic import GetJsonSchemaHandler, GetCoreSchemaHandler
from pydantic.json_schema import JsonSchemaValue
from pydantic_core import core_schema, PydanticCustomError
from typing_extensions import Annotated, Literal
@dataclasses.dataclass
class DateTimeAsString:
type: Literal["date_as_yyyymmdd", "iso_datetime", "any_valid_date"]
def __get_pydantic_json_schema(
self,
core_schema: core_schema.CoreSchema, # type: ignore
handler: GetJsonSchemaHandler
) -> JsonSchemaValue:
field_schema = handler(core_schema)
return field_schema
def __get_pydantic_core_schema__(
self,
source: typing.Any,
handler: GetCoreSchemaHandler
) -> core_schema.CoreSchema: # type: ignore
function_lookup = {
'date_as_yyyymmdd': typing.cast(core_schema.WithInfoValidatorFunction, self.validate_date),
'iso_datetime': typing.cast(core_schema.WithInfoValidatorFunction, self.validate_iso_datetime),
'any_valid_date': typing.cast(core_schema.WithInfoValidatorFunction, self.validate_any_datetime),
}
return core_schema.with_info_after_validator_function(
function_lookup[self.type],
handler(source),
)
@staticmethod
def validate_any_datetime(datestr: str, _: core_schema.ValidationInfo) -> str:
try:
pendulum.parse(datestr, exact=True)
return datestr
except ValueError:
raise PydanticCustomError('invalid_date', 'Not a Valid Date/DateTime')
@staticmethod
def validate_iso_datetime(datestr: str, _: core_schema.ValidationInfo) -> str:
try:
parsed_date = datetime.datetime.strptime(datestr, "%Y-%m-%dT%H:00")
return parsed_date.strftime("%Y-%m-%dT%H:00")
except ValueError:
raise PydanticCustomError('invalid_date', 'invalid date not in YYYY-MM-DDTHH:00')
@staticmethod
def validate_date(datestr: str, _: core_schema.ValidationInfo) -> str:
try:
parsed_date = datetime.datetime.strptime(datestr, "%Y-%m-%d")
return parsed_date.strftime("%Y-%m-%d")
except ValueError:
raise PydanticCustomError('invalid_date', 'invalid date not in YYYY-MM-DD')
def __hash__(self) -> int:
return hash(type(self.type))
WfDateStr = Annotated[str, DateTimeAsString('date_as_yyyymmdd')]
WfDateTimeStr = Annotated[str, DateTimeAsString('iso_datetime')]
WfAnyValidDateTimeStr = Annotated[str, DateTimeAsString('any_valid_date')]
Code language: Python (python)Sample Data Model – Usage of Custom Types in the Data Model
from typing import Literal
from pydantic import ConfigDict
from wf_avro_base_model.base import WfBaseModel
from wf_avro_base_model.custom import WfDateStr
import wealthfront.wf_types as wt
class SampleCustomer(WfBaseModel):
model_config = ConfigDict(arbitrary_types_allowed=True)
first_name: wt.FIRST_NAME()()
favourite_hobby: Literal["music", "chess"]
age: wt.SMALLINT(min_value=20, max_value=70)()
dob: WfDateStr
print(SampleCustomer.fake()) # returns random instance of SampleCustomer with first_name='Scott' favourite_hobby='music' age=60 dob='2015-09-18'
print(SampleCustomer.fake(dob="xyz", age=71, favourite_hobby="piano")) # fails with validation error
# pydantic_core._pydantic_core.ValidationError: 3 validation errors for SampleCustomer
# favourite_hobby
# Input should be 'music' or 'chess' [type=literal_error, input_value='piano', input_type=str]
# For further information visit https://errors.pydantic.dev/2.4/v/literal_error
# age
# Input should be less than or equal to 70 [type=less_than_equal, input_value=71, input_type=int]
# For further information visit https://errors.pydantic.dev/2.4/v/less_than_equal
# dob
# invalid date not in YYYY-MM-DD [type=invalid_date, input_value='xyz', input_type=str]
Code language: Python (python)Bringing It All Together: The Overall Architecture
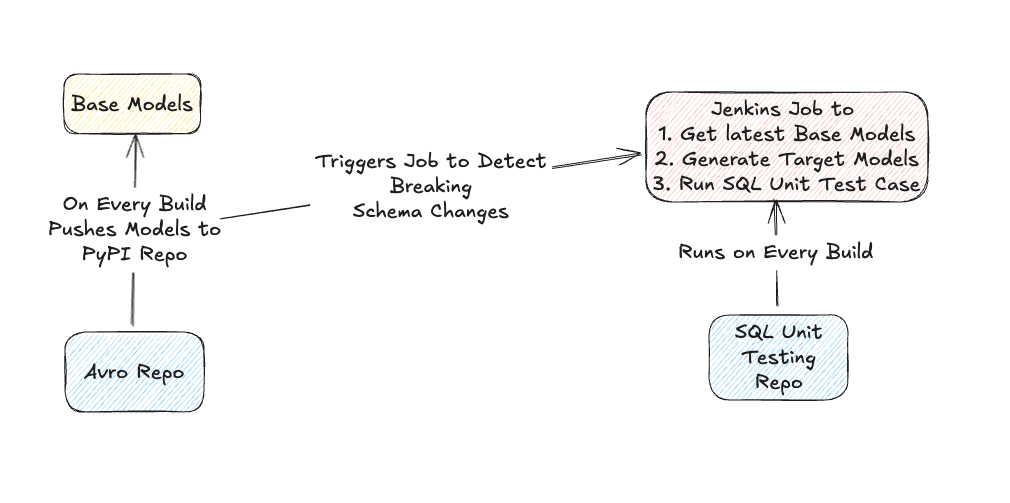
Now that we’ve explored the key components of our SQL testing library, let’s take a step back and look at how everything fits together in our build flow.
At a high level, our architecture ensures that schema changes, test case execution, and validation are all seamlessly integrated into our development pipeline.
How It Works:
Schema Generation & Publishing
- Every time a new build runs in our Avro repository, it automatically generates Base Models for our input source tables.
- These models are then packaged and pushed to a private PyPI repository, making them easily accessible across our data ecosystem.
Automated SQL Unit Test Execution
- The schema update also triggers a Jenkins job responsible for running SQL unit test cases.
- This ensures that any schema changes are immediately tested against existing SQL queries.
Early Detection of Breaking Changes
- If a schema change fails a SQL test case, it is flagged early—before it affects production pipelines.
- Engineers get instant feedback, allowing them to fix compatibility issues proactively.
By automating this process, we eliminate manual effort, reduce errors, and create a safeguard against unintended schema changes. This tight integration between schema evolution and SQL testing ensures that our data pipelines remain robust, reliable, and production-ready.
Challenges
Building a SQL testing library for Athena was far from straightforward. We ran into several challenges, from logging and debugging issues to SQL length limits to adoption hurdles. Here’s a look at the key roadblocks we encountered and how we tackled them:
Making SQL Logs Useful Without Overloading the System
Since we generate fake data dynamically for every test case, our library is great at uncovering edge cases. But this also means that test failures are different each time, making it hard to reproduce issues.
At first, we tried logging the full SQL query in the build logs, but that quickly became impractical due to the query length. To simplify, we switched to logging only the query execution ID. However, this created another challenge—not every developer had access to Athena server logs to retrieve the full query.
💡 What we did: We started saving all test SQLs into a JSON file using pytest’s pytest_runtest_makereport plugin. Then, we used a simple jQuery to let developers copy and debug failed queries with one click. This made debugging much faster and more accessible.
Bridging the Gap Between Python and SQL Data Types
Python and SQL don’t always play nicely together when it comes to data types. For example:
- Python int → Athena BIGINT
- Python str → Athena VARCHAR(N), but without length constraints
Without proper type enforcement, we risked SQL mismatches and silent data issues.
💡 What we did: We built custom Pydantic data types to ensure that our Python models accurately mirror Athena tables, enforcing stricter validation and preventing hidden data errors.
Handling SQL Length Limits as Queries Grew
We designed our library to leave zero or minimal footprint, meaning we avoided creating physical test tables. Instead, we used Common Table Expressions (CTEs) to define test data inline.
But as test cases grew more complex and datasets got larger, SQL queries started hitting Athena’s 256KB query size limit.
💡 What we did: For particularly large queries, we introduced temporary physical views that automatically expire after 30 days. This kept our setup lightweight while avoiding query failures due to size constraints.
Encouraging Adoption for Existing SQL Pipelines
New pipelines quickly adopted the library, but we also wanted to make testing easy for existing SQL workflows without requiring engineers to rewrite everything from scratch.
💡 What we did: We built a simple automation utility that auto-generates SQL test cases from existing queries. This gave teams an easy way to onboard, helping them catch issues immediately without extra effort.
Final Thoughts
This project taught us that SQL testing isn’t just about writing test cases—it’s about making debugging easier, handling real-world constraints, and driving adoption across teams.
By solving these challenges, we built a library that makes SQL testing in Athena practical, scalable, and developer-friendly. And in the end, that’s what matters most—helping teams catch issues early and keep their data pipelines reliable.
Example Test Case Snippet
from typing import List
import pendulum
# Importing Base and Target Data Models
from wf_glue_types.clickstream import ClickstreamIdMapping
from wf_avro_types.avro_py.events import WebEvents, AndroidEvents, IosEvents
from tests.sqltesting.sql_unit_testing_base import SqlUnitTestingBase
# Import Airflow Tasks containing Athena SQL
from wealthfront.dags.data.clickstream.clickstream_id_mapping_dag import load_table_clickstream_id_mapping
from wealthfront.dags.settings import ET
# Example Test Case for the following SQL
# WITH all_clickstream_data AS (
# SELECT
# userid AS external_user_id,
# NULLIF(JSON_EXTRACT_SCALAR(properties, '$.fbclid'), '') AS fbclid,
# etl_time,
# messageid
# FROM "events"."web_events"
# WHERE etl_time BETWEEN '{ETDate.to_iso_format_first_hour()}' AND '{ETDate.to_iso_format_last_hour()}'
# UNION ALL
# SELECT
# userid AS external_user_id,
# NULLIF(JSON_EXTRACT_SCALAR(properties, '$.fbclid'), '') AS fbclid,
# etl_time,
# messageid
# FROM "events"."ios_events"
# WHERE etl_time BETWEEN '{ETDate.to_iso_format_first_hour()}' AND '{ETDate.to_iso_format_last_hour()}'
# UNION ALL
# SELECT
# userid AS external_user_id,
# NULLIF(JSON_EXTRACT_SCALAR(properties, '$.fbclid'), '') AS fbclid,
# etl_time,
# messageid
# FROM "events"."android_events"
# WHERE etl_time BETWEEN '{ETDate.to_iso_format_first_hour()}' AND '{ETDate.to_iso_format_last_hour()}'
# ),
# latest_mapping AS (
# SELECT
# external_user_id,
# MAX_BY(fbclid, etl_time) FILTER (WHERE fbclid IS NOT NULL) AS latest_seen_fbclid
# FROM all_clickstream_data
# WHERE external_user_id is not null
# AND fbclid is not null
# GROUP by external_user_id
# ),
# previous_mapping AS (
# SELECT
# external_user_id,
# first_seen_fbclid,
# latest_seen_fbclid,
# FROM {TableMacro('clickstream.clickstream_id_mapping')}
# WHERE etl_date = '{ETDate.add_days(-1)}'
# )
# SELECT
# COALESCE(cur.external_user_id, yesterday.external_user_id) AS external_user_id,
# COALESCE(yesterday.first_seen_fbclid, cur.latest_seen_fbclid) AS first_seen_fbclid,
# COALESCE(cur.latest_seen_fbclid, yesterday.latest_seen_fbclid) AS latest_seen_fbclid,
# '{ETDate}' AS etl_date
# FROM latest_mapping cur FULL OUTER JOIN previous_mapping yesterday
# ON (cur.external_user_id = yesterday.external_user_id)
class TestClickStreamIdMappingDag(SqlUnitTestingBase):
output_rows: List[ClickstreamIdMapping]
FOO_ID = "USRM-FOOO-AEUZ-CNDN"
BAR_ID = "USRM-BARR-AEUZ-CNDN"
@classmethod
def setUpClass(cls):
# Use Models to create fake data
fake_analytic_android_data_list = [
AndroidEvents.fake(
userId=cls.FOO_ID,
properties='{"fbclid": "fnew1"}',
etl_time="2022-10-25T00:00"
),
]
fake_analytic_ios_data_list = [
IosEvents.fake(
userId=cls.FOO_ID,
properties='{"fbclid": "fnew6"}',
etl_time="2022-10-25T00:00"
),
]
fake_analytic_web_data_list = [
WebEvents.fake(
userId=cls.BAR_ID,
properties='{}',
etl_time="2022-10-25T00:00"
),
WebEvents.fake(
userId=cls.BAR_ID,
properties=None,
etl_time="2022-10-25T01:00"
),
]
fake_click_stream_id_mapping_data_list = [
ClickstreamIdMapping.fake(
external_user_id=cls.FOO_ID,
first_seen_fbclid="f_old",
latest_seen_fbclid="f_old",
etl_date='2022-10-24'
)
]
fake_data_list = [
*fake_analytic_android_data_list,
*fake_analytic_ios_data_list,
*fake_click_stream_id_mapping_data_list,
*fake_analytic_web_data_list
]
# Run SQL with mock data
cls.output_rows = cls.run_sql_with_mock_data(
load_task_or_sql=load_table_clickstream_id_mapping,
mock_run_date=pendulum.datetime(2022, 10, 25, 23, 40, tz=ET),
mock_data=fake_data_list,
target_type=ClickstreamIdMapping
)
def test_record_counts(self):
self.assertEqual(3, len(self.output_rows))
def test_old_records_replaced_with_latest_data(self):
data = list(filter(lambda row: row.external_user_id == self.FOO_ID, self.output_rows))
assert len(data) == 1
final_data: ClickstreamIdMapping = data[0]
self.assertEqual('fnew5', final_data.latest_seen_fbclid)
Code language: Python (python)Disclosures
The information contained in this communication is provided for general informational purposes only, and should not be construed as investment or tax advice. Nothing in this communication should be construed as a solicitation or offer, or recommendation, to buy or sell any security. Any links provided to other server sites are offered as a matter of convenience and are not intended to imply that Wealthfront Advisers or its affiliates endorses, sponsors, promotes and/or is affiliated with the owners of or participants in those sites, or endorses any information contained on those sites, unless expressly stated otherwise.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Please see our Full Disclosure for important details.
Investment management and advisory services are provided by Wealthfront Advisers LLC (“Wealthfront Advisers”), an SEC-registered investment adviser, and brokerage related products, including the Cash Account, are provided by Wealthfront Brokerage LLC (“Wealthfront Brokerage”), a Member of FINRA/SIPC. Financial planning tools are provided by Wealthfront Software LLC (“Wealthfront Software”).
Wealthfront Advisers, Wealthfront Brokerage, and Wealthfront Software are wholly-owned subsidiaries of Wealthfront Corporation.
Copyright 2025 Wealthfront Corporation. All rights reserved.